
Flight Dealy Analysis
§1. Introduction
The aim of this project is to use the data set provided by the U.S. Department of Transportation (DOT) Bureau of Transportation Statistics to analyze factors to predict the number of Total flight and punctuality rate for each day. I want to use the LSTM(Long Short-Term Memory) to help me get the result. The ultimate goal of the project is help people travel more efficiently and know the relationship between flight and weather.
from plotly import express as px
from keras.models import Sequential
from tensorflow.keras.layers import Dropout, Dense, LSTM
import numpy as np
import pandas as pd
import plotly.io as pio
import matplotlib.pyplot as plt
from sklearn import preprocessing
from sklearn.preprocessing import OneHotEncoder
import sqlite3#sqlite3 python module that lets us interact wtih squile
import tensorflow as tf
from tensorflow.keras.layers.experimental import preprocessing
from tensorflow.keras import layers
import warnings
warnings.filterwarnings('ignore')
from datetime import datetime
import re
import time
import datetime
§2. Data preparation
1)Flight Data
Flight2016=pd.read_csv("2016.csv")
Flight2015=pd.read_csv("2015.csv")
Flight2017=pd.read_csv("2017.csv")
Flight2018=pd.read_csv("2018.csv")
Flight2014=pd.read_csv("2014.csv")
Flight2013=pd.read_csv("2013.csv")
Flight2012=pd.read_csv("2012.csv")
Because LSTM(Long Short-Term Memory) is one of the deep learning techniques, as much data as possible will help me get more accurate results, so I downloaded all the original flight data from 2012-2018, the following function will perform the most basic data The cleaning work is to facilitate the subsequent splicing of other datasets to form a complete structure.
From the raw data, we found that there are a total of 28 columns in the flight dataset. If the unit of our prediction is every flight instead of every day, I will select predictors through correlation plot or heat map, but in this project, the object we explore is the unit of day, so after data cleaning, Most columns will be removed, or converted to other varibles.
Flight2016.head()
| FL_DATE | OP_CARRIER | OP_CARRIER_FL_NUM | ORIGIN | DEST | CRS_DEP_TIME | DEP_TIME | DEP_DELAY | TAXI_OUT | WHEELS_OFF | ... | CRS_ELAPSED_TIME | ACTUAL_ELAPSED_TIME | AIR_TIME | DISTANCE | CARRIER_DELAY | WEATHER_DELAY | NAS_DELAY | SECURITY_DELAY | LATE_AIRCRAFT_DELAY | Unnamed: 27 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 2016-01-01 | DL | 1248 | DTW | LAX | 1935 | 1935.0 | 0.0 | 23.0 | 1958.0 | ... | 309.0 | 285.0 | 249.0 | 1979.0 | NaN | NaN | NaN | NaN | NaN | NaN |
| 1 | 2016-01-01 | DL | 1251 | ATL | GRR | 2125 | 2130.0 | 5.0 | 13.0 | 2143.0 | ... | 116.0 | 109.0 | 92.0 | 640.0 | NaN | NaN | NaN | NaN | NaN | NaN |
| 2 | 2016-01-01 | DL | 1254 | LAX | ATL | 2255 | 2256.0 | 1.0 | 19.0 | 2315.0 | ... | 245.0 | 231.0 | 207.0 | 1947.0 | NaN | NaN | NaN | NaN | NaN | NaN |
| 3 | 2016-01-01 | DL | 1255 | SLC | ATL | 1656 | 1700.0 | 4.0 | 12.0 | 1712.0 | ... | 213.0 | 193.0 | 173.0 | 1590.0 | NaN | NaN | NaN | NaN | NaN | NaN |
| 4 | 2016-01-01 | DL | 1256 | BZN | MSP | 900 | 1012.0 | 72.0 | 63.0 | 1115.0 | ... | 136.0 | 188.0 | 121.0 | 874.0 | 72.0 | 0.0 | 52.0 | 0.0 | 0.0 | NaN |
5 rows × 28 columns
conn=sqlite3.connect("project.db")#create data base called project
def flight_data_each_year(Flight):
Flight.fillna(0,inplace=True)#because NA means there is no delay so we can fill it with 0
LAX=Flight[Flight["ORIGIN"]=="LAX"]#Because there is too much data for each year of takeoff, hence we will study the planes taking off from LAX
LAX["delay"]=(LAX[["CARRIER_DELAY","WEATHER_DELAY","NAS_DELAY","SECURITY_DELAY","LATE_AIRCRAFT_DELAY"]] != 0).astype(int).sum(axis=1)
#There are many reasons for flight delay, and we only care whether a flight is delayed, so we need to add all the reasons,
#if it is greater than or equal to 1which means it is delayed
LAX["delay"][LAX.delay>1]=1#Turn multiple reasons into 1
cols=["FL_DATE","delay"]#
LAX=LAX[cols]
LAX.to_sql("LAX", conn, if_exists = "replace", index = False)#put LAX.csv to the data base
#Call sql to calculate the total number of flights per day and the total number of delayed flights
#(because when delay==0, it means there is no delay, so you only need to add all the delays to know the total number of delays)
cmd = """
SELECT *, count() AS Total_flight_per_day, SUM(delay) AS Total_Delay_per_day
FROM LAX
GROUP BY FL_DATE
"""
LAX_flight = pd.read_sql_query(cmd, conn)
LAX_flight["punctuality rate"]=1-LAX_flight["Total_Delay_per_day"]/LAX_flight["Total_flight_per_day"]#计算每一天的准点率
LAX_flight["week"] = ''#Create a new column named week
for i in range(len(LAX_flight["FL_DATE"])):
#Call the datetime package to standardize the time to get the day of the week for each day
LAX_flight["week"][i]=datetime.datetime.strptime(LAX_flight["FL_DATE"].iloc[i],"%Y-%m-%d").isoweekday()
#Because the output result only corresponds to the number of the week, so we need to convert it into English text
LAX_flight["week"]=LAX_flight["week"].replace({5:'Friday',
1:'Monday',
2:'Tuesday',
3:'Wednesday',
4:'Thursday',
6:'Saturday',
7:'Sunday'
})
#Because we need to use a neural network in the end, we need to use OneHotEncode for categorical variables
encoder = OneHotEncoder(handle_unknown='ignore')
#perform one-hot encoding on 'week' column
encoder_df = pd.DataFrame(encoder.fit_transform(LAX_flight[['week']]).toarray())
# #merge one-hot encoded columns back with original DataFrame
LAX_flight = LAX_flight.join(encoder_df)
# #view final df
#LAX_flight.drop(labels=['week'], axis=1, inplace=True)
colNameDict = {0:'Friday',
1:'Monday',
2:'Saturday',
3:'Sunday',
4:'Thursday',
5:'Tuesday',
6:'Wednesday',
}
LAX_flight.rename(columns = colNameDict,inplace=True)
LAX_flight.drop(labels=['Total_Delay_per_day','delay'],axis=1, inplace=True)
return LAX_flight
LAX_flight2016=flight_data_each_year(Flight2016)
LAX_flight2015=flight_data_each_year(Flight2015)
LAX_flight2017=flight_data_each_year(Flight2017)
LAX_flight2018=flight_data_each_year(Flight2018)
LAX_flight2014=flight_data_each_year(Flight2014)
LAX_flight2013=flight_data_each_year(Flight2013)
LAX_flight2012=flight_data_each_year(Flight2012)
LAX_flight=pd.concat([LAX_flight2015,LAX_flight2016,LAX_flight2017,LAX_flight2018])
#Because the amount of data is too large, it is necessary to group the data sets to combine
LAX_flight=pd.concat([LAX_flight,LAX_flight2012,LAX_flight2013,LAX_flight2014])
LAX_flight
| FL_DATE | Total_flight_per_day | punctuality rate | week | Friday | Monday | Saturday | Sunday | Thursday | Tuesday | Wednesday | |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 2015-01-01 | 556 | 0.766187 | Thursday | 0.0 | 0.0 | 0.0 | 0.0 | 1.0 | 0.0 | 0.0 |
| 1 | 2015-01-02 | 640 | 0.656250 | Friday | 1.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 |
| 2 | 2015-01-03 | 575 | 0.526957 | Saturday | 0.0 | 0.0 | 1.0 | 0.0 | 0.0 | 0.0 | 0.0 |
| 3 | 2015-01-04 | 615 | 0.536585 | Sunday | 0.0 | 0.0 | 0.0 | 1.0 | 0.0 | 0.0 | 0.0 |
| 4 | 2015-01-05 | 622 | 0.667203 | Monday | 0.0 | 1.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 360 | 2014-12-27 | 564 | 0.734043 | Saturday | 0.0 | 0.0 | 1.0 | 0.0 | 0.0 | 0.0 | 0.0 |
| 361 | 2014-12-28 | 604 | 0.743377 | Sunday | 0.0 | 0.0 | 0.0 | 1.0 | 0.0 | 0.0 | 0.0 |
| 362 | 2014-12-29 | 627 | 0.733652 | Monday | 0.0 | 1.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 |
| 363 | 2014-12-30 | 614 | 0.547231 | Tuesday | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 1.0 | 0.0 |
| 364 | 2014-12-31 | 493 | 0.748479 | Wednesday | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 1.0 |
2557 rows × 11 columns
We used One-Hot Encoding instead of our commonly used label Encoding in the above processing of the week. Because the premise of using label Encoding is that the variable should behave to some extent, for example, easy is 1, medium is 2, difficult is 3. But in our case the day of the week does not represent such an attribute so I used One- Hot Encoding. In fact, One-Hot Encoding is very easy to understand. Each corresponding value is only 0 and 1. 0 means it does not have the property, and 1 means it has the property. For example, on 2015-01-01, the value corresponding to Thursday is 1, which means that 2015-01-01 is Thursday.
2) visulazation
fig = px.line(data_frame = LAX_flight2015, # data that needs to be plotted
x = "FL_DATE", # column name for x-axis
y = "Total_flight_per_day",
markers=True,
color = "week", # column name for color coding
width = 1000,
height = 500)
# reduce whitespace
fig.update_layout(margin={"r":0,"t":0,"l":0,"b":0})
# show the plot
fig.show()
fig = px.line(data_frame = LAX_flight2015, # data that needs to be plotted
x = "FL_DATE", # column name for x-axis
y = "punctuality rate",
markers=True,
color = "week", # column name for color coding
width = 1000,
height = 500)
# reduce whitespace
fig.update_layout(margin={"r":0,"t":0,"l":0,"b":0})
# show the plot
fig.show()
pio.write_html(fig, file='flight2.html', auto_open=True)
According to the image, we can conclude that the overall flight punctuality rate tends to be a stable sequence, that is, a sequence with no obvious upward or downward trend, and the average punctuality rate is about 70%-90%. The punctuality rate is inversely proportional, which is also in line with our intuition that the punctuality rate of the aircraft is not high when the shipping pressure is high. When we look at the data corresponding to the number of days, we find that the weather should be a very important factor. Therefore, the next part of the code is mainly to deal with the weather conditions in the Los Angeles area from 2012 to 2018.
3) Weather Data
weather = pd.read_csv("weather2012_2018.csv")
weather.head()
| local_time LA (airport) | Ff | N | VV | Td | RRR | |
|---|---|---|---|---|---|---|
| 0 | 31.12.2018 22:00 | 2.0 | 20-0%. | 16 | -12.2 | NaN |
| 1 | 31.12.2018 16:00 | 4.0 | 50%. | 16 | 6.7 | NaN |
| 2 | 31.12.2018 10:00 | 2.0 | 70 -80%. | 16 | 7.8 | NaN |
| 3 | 31.12.2018 04:00 | 2.0 | 50%. | 16 | 6.1 | NaN |
| 4 | 30.12.2018 22:00 | 3.0 | 20-0%. | 16 | 8.3 | NaN |
Before processing, let’s take a look at the raw data. We found that the monitoring station will measure 4 times a day, the first time is 22:00, the second time is 16:00, the third time is 10:10, and the fourth time is 22:00. But don’t forget that the unit of our final data is each day, so the time doesn’t matter, so in the function below, we will deal with the time. And the varible name of the original data is not very clear, so we have to rename the variable name to help everyone better understand the corresponding real meaning.
def weather_data_each_year(Weather):
Weather.fillna(0,inplace=True)
Weather['local_time LA (airport)'] = pd.to_datetime(Weather['local_time LA (airport)'])#normalize time
Weather["Day_time"]=Weather["local_time LA (airport)"].apply(lambda x:str(x)[0:10])#only need day don't care about hours and min
cols=["Day_time",'local_time LA (airport)',"Ff","N","RRR","VV"]
Weather=Weather[cols]
Weather.columns = ["Day_time",'Observation_time', 'wind_speed',"cloud", 'precipitation', 'visibility']#rename
Weather["precipitation"]=Weather["precipitation"].replace("Signs of precipitation", 0)
Weather["cloud"]=Weather["cloud"].replace({'100%.':1,#Convert percentages to corresponding decimals for subsequent calculations
'70 -80%.':0.75,
'50%.':0.5,
0:0,
'The sky is not visible due to fog and/or other meteorological phenomena.':0,
'20-0%.':0.1,
'Cloudless':0
})
Weather.to_sql("Weather", conn, if_exists = "replace", index = False)#put Weather.csv to the data base"\
#cmd will calculate average wind speed, average visibility, total precipitation per day
cmd = """
SELECT Day_time,AVG(wind_speed) AS wind_speed_perday,AVG(visibility) AS visibility_perday, AVG(cloud) AS cloud_perday ,SUM(precipitation) AS precipitation_perday
FROM Weather
GROUP BY Day_time
"""
LAX_weather= pd.read_sql_query(cmd, conn)
#Convert real cloud cover according to real weather
for i in range(len(LAX_weather["cloud_perday"])):
if(LAX_weather["cloud_perday"][i]==0):
LAX_weather["cloud_perday"][i]='cloudless'
elif(LAX_weather["cloud_perday"][i]<0.3):
LAX_weather["cloud_perday"][i]='less cloudy'
elif(LAX_weather["cloud_perday"][i]<0.7):
LAX_weather["cloud_perday"][i]='cloudy'
else:
LAX_weather["cloud_perday"][i]="overcast"
#Convert precipitation to heavy, medium and light rain
for i in range(len(LAX_weather["precipitation_perday"])):
if(LAX_weather["precipitation_perday"][i]==0):
LAX_weather["precipitation_perday"][i]="no_rain"
elif(LAX_weather["precipitation_perday"][i]<10):
LAX_weather["precipitation_perday"][i]="light_rain"
elif(LAX_weather["precipitation_perday"][i]<25):
LAX_weather["precipitation_perday"][i]="moderate_rain"
else:
LAX_weather["precipitation_perday"][i]="heavy_rain"
#creating instance of one-hot-encoder
encoder = OneHotEncoder(handle_unknown='ignore')
#perform one-hot encoding on ['cloud_perday','precipitation_perday'] column
encoder_df = pd.DataFrame(encoder.fit_transform(LAX_weather[['cloud_perday','precipitation_perday']]).toarray())
#merge one-hot encoded columns back with original DataFrame
LAX_weather = LAX_weather.join(encoder_df)
#view final df
LAX_weather.drop(labels=['cloud_perday','precipitation_perday'], axis=1, inplace=True)
colNameDict = {0:'cloudless',
1:'cloudy',
2:'fog',
3:'less cloudy',
4:'overcast',
5:'heavy_rain',
6:'light_rain',
7:'moderate_rain',
8:'no_rain'
}
LAX_weather.rename(columns = colNameDict,inplace=True)
return LAX_weather
LAX_weather=weather_data_each_year(weather)
LAX_weather
| Day_time | wind_speed_perday | visibility_perday | cloudless | cloudy | fog | less cloudy | overcast | heavy_rain | light_rain | moderate_rain | |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 2012-01-01 | 2.00 | 14.0 | 0.0 | 0.0 | 1.0 | 0.0 | 0.0 | 0.0 | 0.0 | 1.0 |
| 1 | 2012-01-02 | 1.75 | 14.0 | 0.0 | 1.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 1.0 |
| 2 | 2012-01-03 | 2.75 | 16.0 | 0.0 | 1.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 1.0 |
| 3 | 2012-01-04 | 5.50 | 16.0 | 0.0 | 0.0 | 1.0 | 0.0 | 0.0 | 0.0 | 0.0 | 1.0 |
| 4 | 2012-01-05 | 3.50 | 13.5 | 0.0 | 0.0 | 0.0 | 1.0 | 0.0 | 1.0 | 0.0 | 0.0 |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 2552 | 2018-12-27 | 5.25 | 16.0 | 0.0 | 1.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 1.0 |
| 2553 | 2018-12-28 | 2.50 | 16.0 | 0.0 | 0.0 | 1.0 | 0.0 | 0.0 | 0.0 | 0.0 | 1.0 |
| 2554 | 2018-12-29 | 2.00 | 16.0 | 0.0 | 0.0 | 1.0 | 0.0 | 0.0 | 0.0 | 0.0 | 1.0 |
| 2555 | 2018-12-30 | 3.00 | 16.0 | 0.0 | 0.0 | 1.0 | 0.0 | 0.0 | 0.0 | 0.0 | 1.0 |
| 2556 | 2018-12-31 | 2.50 | 16.0 | 0.0 | 1.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 1.0 |
2557 rows × 11 columns
From the above table, it can be found that I calculated the average wind speed and visibility for each day, and for the calculation of precipitation I used the sum function to sum instead of the average. This is because the precipitation after sum is a more accurate, but the wind speed and visibility cannot be used in the same way, because it does not have any meaning when we do the addition. Finally, I convert the precipitation and cloud conditions into categorical varibles according to the real division criteria. At the same time, perform One-Hot Encoding processing on it.
4) Merge datasets
LAX_weather.to_sql("LAX_weather", conn, if_exists = "replace", index = False)#put temps.csv to the data base"
LAX_flight.to_sql("LAX_flight", conn, if_exists = "replace", index = False)#put temps.csv to the data base"
2557
cmd = """
SELECT *
FROM LAX_flight
LEFT JOIN LAX_weather ON LAX_weather.Day_time = LAX_flight.FL_DATE
"""
data = pd.read_sql_query(cmd, conn)
#min max normalization
for column in data[["wind_speed_perday","visibility_perday","Total_flight_per_day"]]:
data[column] = (data[column] - data[column].min()) / (data[column].max() - data[column].min())
We call SQL again, because the LEFT JOINT function will help us merge data set. The resulting data is the final dataset. However, at the same time we also normalized the numerical varible in the data. And this time we are using the Min-Max method instead of the standard scaler. Because I found that our data is not a normal distribution, so Min-Max will be more suitable for our project.
sorted_df = data.sort_values(by='FL_DATE')
sorted_df=sorted_df.drop(labels=["Day_time","week"],axis=1)
sorted_df
| FL_DATE | Total_flight_per_day | punctuality rate | Friday | Monday | Saturday | Sunday | Thursday | Tuesday | Wednesday | wind_speed_perday | visibility_perday | cloudless | cloudy | fog | less cloudy | overcast | heavy_rain | light_rain | moderate_rain | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 1461 | 2012-01-01 | 0.585366 | 0.778966 | 0.0 | 0.0 | 0.0 | 1.0 | 0.0 | 0.0 | 0.0 | 0.200 | 0.871176 | 0.0 | 0.0 | 1.0 | 0.0 | 0.0 | 0.0 | 0.0 | 1.0 |
| 1462 | 2012-01-02 | 0.881098 | 0.653495 | 0.0 | 1.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.175 | 0.871176 | 0.0 | 1.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 1.0 |
| 1463 | 2012-01-03 | 0.673780 | 0.806780 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 1.0 | 0.0 | 0.275 | 1.000000 | 0.0 | 1.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 1.0 |
| 1464 | 2012-01-04 | 0.637195 | 0.787197 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 1.0 | 0.550 | 1.000000 | 0.0 | 0.0 | 1.0 | 0.0 | 0.0 | 0.0 | 0.0 | 1.0 |
| 1465 | 2012-01-05 | 0.740854 | 0.900327 | 0.0 | 0.0 | 0.0 | 0.0 | 1.0 | 0.0 | 0.0 | 0.350 | 0.838969 | 0.0 | 0.0 | 0.0 | 1.0 | 0.0 | 1.0 | 0.0 | 0.0 |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 1456 | 2018-12-27 | 0.908537 | 0.656672 | 0.0 | 0.0 | 0.0 | 0.0 | 1.0 | 0.0 | 0.0 | 0.525 | 1.000000 | 0.0 | 1.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 1.0 |
| 1457 | 2018-12-28 | 0.896341 | 0.707391 | 1.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.250 | 1.000000 | 0.0 | 0.0 | 1.0 | 0.0 | 0.0 | 0.0 | 0.0 | 1.0 |
| 1458 | 2018-12-29 | 0.753049 | 0.735390 | 0.0 | 0.0 | 1.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.200 | 1.000000 | 0.0 | 0.0 | 1.0 | 0.0 | 0.0 | 0.0 | 0.0 | 1.0 |
| 1459 | 2018-12-30 | 0.868902 | 0.813456 | 0.0 | 0.0 | 0.0 | 1.0 | 0.0 | 0.0 | 0.0 | 0.300 | 1.000000 | 0.0 | 0.0 | 1.0 | 0.0 | 0.0 | 0.0 | 0.0 | 1.0 |
| 1460 | 2018-12-31 | 0.615854 | 0.861646 | 0.0 | 1.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.250 | 1.000000 | 0.0 | 1.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 1.0 |
2557 rows × 20 columns
Before dividing the data into training set and test set, we need to reorder the data, because our standard of division is to divide the data into 60% training set, 20% vaildation group and 20% test set in chronological order rather than randomly.
§3. training,validation,and testing group
# 60% train, 20% validation, 20% test
train_size = int(0.6*len(sorted_df ))
val_size = int(0.2*len(sorted_df ))
train = sorted_df [:train_size]
val = sorted_df [train_size : train_size + val_size]
test = sorted_df [train_size + val_size:]
from sklearn.model_selection import train_test_split
#split into X and y
X_train=train.drop(['Total_flight_per_day','punctuality rate','FL_DATE'],axis=1)
y_train=train[['Total_flight_per_day','punctuality rate']]
#split into X and y
X_val=val.drop(['Total_flight_per_day','punctuality rate','FL_DATE'],axis=1)
y_val=val[['Total_flight_per_day','punctuality rate']]
#split into X and y
X_test=test.drop(['Total_flight_per_day','punctuality rate','FL_DATE'],axis=1)
y_test=test[['Total_flight_per_day','punctuality rate']]
def create_sequence(values, time_steps):
output = []
for i in range(len(values) - time_steps):
output.append(values[i : (i + time_steps)])
return np.stack(output)
X_train = create_sequence(X_train, 7)
X_test = create_sequence(X_test, 7)
X_val = create_sequence(X_val, 7)
y_train = y_train[-X_train.shape[0]:]
y_test = y_test[-X_test.shape[0]:]
y_val = y_test[-X_val.shape[0]:]
X_train.shape
(1527, 7, 17)
The above create_sequence function can convert our 2D data into a 3D array because the input of the LSTM is always a 3D array. We have a total of 1533 training data. So far all the preparatory work is over.
§4. Model Selection
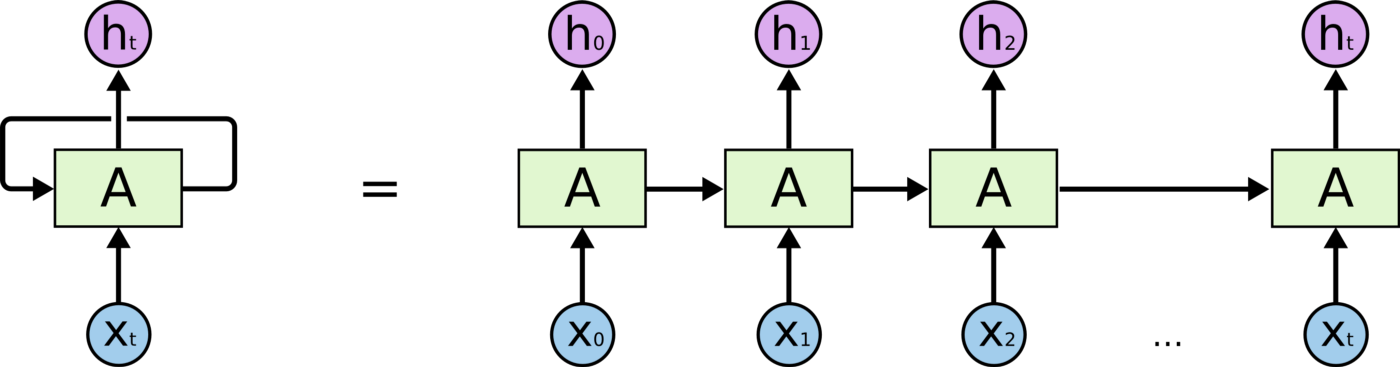
When we got the data ready we decided to use keras’ sequential model to construct the training model. For an ordinary neural network, whenever it completes one thing and outputting the result, it will forget the past, and when new variables enter the network, it will only make predictions based on new inputs. However, human thinking is not like this. Instead of throwing everything away and starting from scratch, we apply old and newly acquired information to get new answers. And RNNs work very similar to the way humans think. But RNN is not omnipotent. When the old information and the new input information are too far away, it will lose the ability to learn such distant information. And in the process, we may lose very important information, making predictions inaccurate. The solution is LSTM, a variant of RNN. LSTM does not remember every information, but remembers important information and brings it into the next operation, and automatically discards unimportant factors. The process of implementation is to introduce three important principles, input gate, an output gate and a forget gate. Considering that the weather will have a continuous impact on the alignment rate, the LSTM recurrent neural network is used here to make predictions, using Dense(2) , so that our output model can output two results, the first result is the prediction effect of the number of flights on the second day, and the second result is the prediction result of the punctuality rate on the second day. The picture below is a sample RNN that can help us to understand the concept.
from tensorflow.keras.layers import Bidirectional
model = Sequential()
# Adding a LSTM layer
model.add(LSTM(32,return_sequences=False,input_shape=(X_train.shape[1],X_train.shape[-1])))
model.add(Dense(2))
model.add(tf.keras.layers.Activation('sigmoid'))
model.compile(loss='binary_crossentropy',optimizer='AdaDelta',metrics=['accuracy'])
model.summary()
Model: "sequential"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
lstm (LSTM) (None, 32) 6400
_________________________________________________________________
dense (Dense) (None, 2) 66
_________________________________________________________________
activation (Activation) (None, 2) 0
=================================================================
Total params: 6,466
Trainable params: 6,466
Non-trainable params: 0
_________________________________________________________________
callback = tf.keras.callbacks.EarlyStopping(monitor='loss', patience=20)
history = model.fit(X_train,
y_train,
validation_data=(X_val, y_val),
epochs = 500,
verbose = False,
batch_size=50,
callbacks=[callback]
)
plt.plot(history.history['loss'])
plt.plot(history.history['val_loss'])
plt.title('model train vs validation loss')
plt.ylabel('loss')
plt.xlabel('epoch')
plt.legend(['train','testing'], loc='upper right')
plt.show()
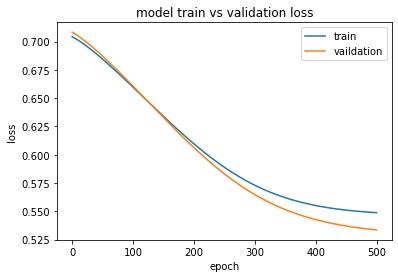
It can be seen that our effect is still good! Because the loss of vaildation has been declining.
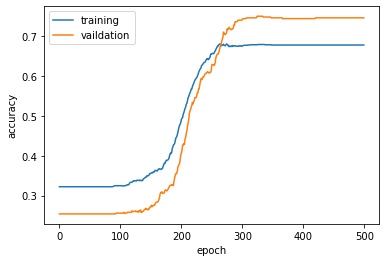
import matplotlib.pyplot as plt
plt.plot(history.history["accuracy"], label = "training")
plt.plot(history.history["val_accuracy"], label = "vaildation")
plt.gca().set(xlabel = "epoch", ylabel = "accuracy")
plt.legend()
<matplotlib.legend.Legend at 0x1f823099e80>
model.evaluate(X_test,y_test)
16/16 [==============================] - 0s 719us/step - loss: 0.5275 - accuracy: 0.7446
[0.5275416970252991, 0.7445544600486755]
The accuracy of the model finally reached 74% because only the weather factor is used, so the accuracy is pretty good. Of course, during model training, we can also adjust its window size, training times, batch size, dropout ratio, etc. When time is sufficient, the model can be adjusted repeatedly to obtain better prediction results.
5. Web Tech
For basic uses of flask such as render_template, html introduce, post, get, and etc. Please check this post
In this project, we use to flask add more functionality such as output dataframe and embeding plotly plots into the web
(1) output dataframe (convert into table format of HTML)
@app.route('/Data_preparation/')
def Data_preparation():
df0 = pd.read_csv(r"data\flights_original.csv").iloc[:,:10]
df1 = web_helper.LAX_table()
df2 = web_helper.weather_data()
df3 = web_helper.weather_data_each_year(pd.read_csv(r"data\weather2012_2018.csv"))
df4 = web_helper.merge_data(df3, df1)
return render_template('Data_preparation.html', table0=[df0.iloc[:10].to_html(classes='data', header="true")],
table1=[df1.iloc[:10].to_html(classes='data', header="true")],
table2=[df2.iloc[:10].to_html(classes='data', header="true")],
table3=[df3.iloc[:10].to_html(classes='data', header="true")],
table4=[df4.iloc[:10].to_html(classes='data', header="true")])
When we open the section ‘/Data_preparation/’ page, app.py will call the function Data_preparation(), inside this function call, we have functions to import and return corresponding data frames and assigned them with the name df0 to df4. before we need render these dataframes into html form by using pd.to_html(replace pd with dataframe object).
In the html, we also need place holder for these tables:
<figure class="table">
<figcaption><small>Original Flights Data</small></figcaption>
</figure>
the to_html method returns a query string (similar to the list of lists here), so we need for loop here to embed each element in the table
(2) plotly plots
def plotly_flights(year):
LAX_flight = pd.read_csv(r"data\LAX_flight.csv")
fig = px.line(data_frame = LAX_flight[LAX_flight['FL_DATE'].str.contains(pat = str(year))], # data that needs to be plotted
x = "FL_DATE", # column name for x-axis
y = "Total_flight_per_day",
markers=True,
color = "week", # column name for color coding
width = 800,
height = 500)
# reduce whitespace
fig.update_layout(margin={"r":0,"t":0,"l":0,"b":0})
# show the plot
return fig
Similar to the functions that we used to return data frame, this function creates plots by using plotly.
The year argument let users to choose which year of data they want to observe.
Under the same idea, we convert plotly object into a JSON query string that JavaScript could understand, then render it with the ‘Data_preparation.html’ template.
fig1 = web_helper.plotly_flights(request.form["year"])
graphJSON1 = json.dumps(fig1, cls=plotly.utils.PlotlyJSONEncoder)
return render_template('Data_preparation.html', graphJSON_object = graphJSON1)
There also is a place holder in the ‘Data_preparation.html’:
<span id="chart1"></span>
<script src='https://cdn.plot.ly/plotly-latest.min.js'></script>
<script type='text/javascript'>
var graphs1 = ;
Plotly.newPlot('chart1',graphs1,{});
</script>
Here, we need few more steps to actually make a plot that HTML could ‘understand’. ‘’ import the JavaScript package which use to convert JSON string to HTML. Plotly.newPlot() is the function of the package. ‘chart1’ is the id, which tells where to ‘draw’ the plot. The first line is the place where plot should be draw.